Analyzing the Moving Parts of a Large-Scale Multi-label Text Classification Pipeline: Experiences in Indexing Biomedical Articles
Anthony Rios and Ramakanth Kavuluru.
In proceedings of the 2015 International Conference on Healthcare Informatics (ICHI).
Abstract:
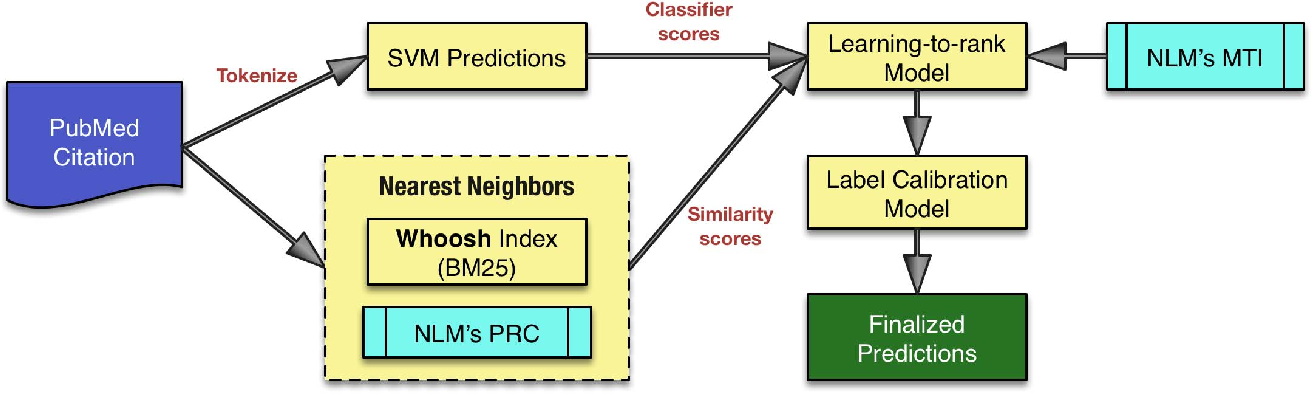
Medical subject headings (MeSH) is a controlled hierarchical vocabulary used by the National Library of Medicine (NLM) to index biomedical articles. In the 2014 version of MeSH terminology there are a total of 27,149 terms. Librarians at the NLM tag each biomedical article to be indexed for the PubMed literature search system with terms from MeSH. This means the human indexers look at each article’s full text and index it with a small set of descriptors, 13 on average, from over 27,000 descriptors available in MeSH. There have been many recent attempts to automate this process focused on using the article title and abstract text to predict MeSH terms for the corresponding article. There has also been an open automated biomedical indexing challenge, BioASQ, that started in 2013. The best general supervised learning framework in these challenges has been a pipeline with four different components: 1. pre-processing and feature extraction; 2. employing the binary relevance and/or nearest neighbor approaches to select a set of candidate terms; 3. ranking these candidate terms using corresponding informative features; and 4. applying label calibration to dynamically predict the number of top terms to be included in the final selection for the current instance. The specific details in how each of these components is implemented determines the performance variations of various entries in the challenge. In this paper, we analyze these moving parts of the MeSH indexing multilabel classification pipeline with experiments involving different combinations. Our best combination achieves ≈ 1% increase in micro F-score compared with the top performing team across the five weeks of the final batch of the BioASQ 2014 challenge. The main take away from our efforts is that small improvements/modifications to different components of the pipeline can offer moderate improvements to the overall performance of the method. Our experiences show that, at least thus far, top performances have resulted mostly due to these improvements rather than drastic changes of the core methodology.
[Link]
@inproceedings{Rios:2015:AMP:2862752.2863332,
author = {Rios, Anthony and Kavuluru, Ramakanth},
title = {Analyzing the Moving Parts of a Large-Scale Multi-label Text Classification Pipeline: Experiences in Indexing Biomedical Articles},
booktitle = {Proceedings of the 2015 International Conference on Healthcare Informatics},
series = {ICHI '15},
year = {2015},
isbn = {978-1-4673-9548-9},
pages = {1--7},
numpages = {7},
url = {http://dx.doi.org/10.1109/ICHI.2015.6},
doi = {10.1109/ICHI.2015.6},
acmid = {2863332},
publisher = {IEEE Computer Society},
address = {Washington, DC, USA},
}