Few-Shot and Zero-Shot Multi-Label Learning for Structured Label Spaces
Anthony Rios and Ramakanth Kavuluru
In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018).
Abstract:
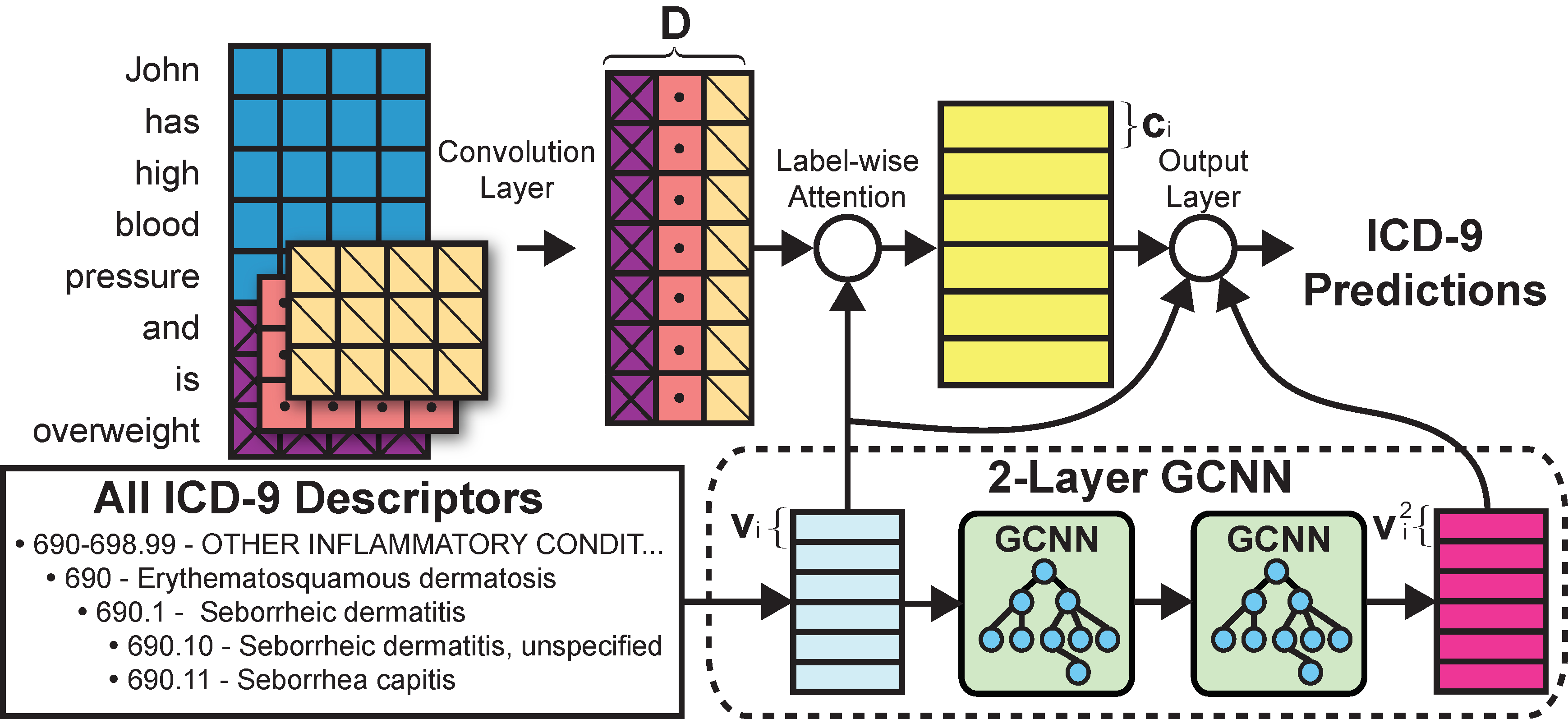
Large multi-label datasets contain labels that occur thousands of times (frequent group), those that occur only a few times (few-shot group), and labels that never appear in the training dataset (zero-shot group). Multi-label few- and zero-shot label prediction is mostly unexplored on datasets with large label spaces, especially for text classification. In this paper, we perform a fine-grained evaluation to understand how state-of-the-art methods perform on infrequent labels. Furthermore, we develop few- and zero-shot methods for multi-label text classification when there is a known structure over the label space, and evaluate them on two publicly available medical text datasets: MIMIC II and MIMIC III. For few-shot labels we achieve improvements of 6.2% and 4.8% in R@10 for MIMIC II and MIMIC III, respectively, over prior efforts; the corresponding R@10 improvements for zero-shot labels are 17.3% and 19%.
@InProceedings{D18-1352,
author = "Rios, Anthony
and Kavuluru, Ramakanth",
title = "Few-Shot and Zero-Shot Multi-Label Learning for Structured Label Spaces",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing",
year = "2018",
publisher = "Association for Computational Linguistics",
pages = "3132--3142",
location = "Brussels, Belgium",
url = "http://aclweb.org/anthology/D18-1352"
}